SERIOUS CONFUSION with Resource Timing
or “Duration includes Blocking”
Resource Timing is a great way to measure how quickly resources download. Unfortunately, almost everyone I’ve spoken with does this using the “duration” attribute and are not aware that “duration” includes blocking time. As a result, “duration” time values are (much) greater than the actual download time, giving developers unexpected results. This issue is especially bad for cross-origin resources where “duration” is the only metric available. In this post I describe the problem and a proposed solution.
Resource Timing review
The Resource Timing specification defines APIs for gathering timing metrics for each resource in a web page. It’s currently available in Chrome, Chrome for Android, IE 10-11, and Opera. You can gather a list of PerformanceEntry objects using getEntries(), getEntriesByType(), and getEntriesByName(). A PerformanceEntry has these properties:
- name – the URL
- entryType – typically “resource”
- startTime – time that the resource started getting processed (in milliseconds relative to page navigation)
- duration – total time to process the resource (in milliseconds)
The properties above are available for all resources – both same-origin and cross-origin. However, same-origin resources have additional properties available as defined by the PerformanceResourceTiming interface. They’re self-explanatory and occur pretty much in this chronological order:
- redirectStart
- redirectEnd
- fetchStart
- domainLookupStart
- domainLookupEnd
- connectStart
- connectEnd
- secureConnectionStart
- requestStart
- responseStart
- responseEnd
Here’s the canonical processing model graphic that shows the different phases. Note that “duration” is equal to (responseEnd – startTime).

Take a look at my post Resource Timing Practical Tips for more information on how to use Resource Timing.
Unexpected blocking bloat in “duration”
The detailed PerformanceResourceTiming properties are restricted to same-origin resources for privacy reasons. (Note that any resource can be made “same-origin” by using the Timing-Allow-Origin response header.) About half of the resources on today’s websites are cross-origin, so “duration” is the only way to measure their load time. And even for same-origin resources, “duration” is the only delta provided, presumably because it’s the most important phase to measure. As a result, all of the Resource Timing implementations I’ve seen use “duration” as the primary performance metric.
Unfortunately, “duration” is more than download time. It also includes “blocking time” – the delay between when the browser realizes it needs to download a resource to the time that it actually starts downloading the resource. Blocking can occur in several situations. The most typical is when there are more resources than TCP connections. Most browsers only open 6 TCP connections per hostname, the exceptions being IE10 (8 connections), and IE11 (12 connections).
This Resource Timing blocking test page has 16 images, so some images incur blocking time no matter which browser is used. Each of the images is programmed on the server to have a 1 second delay. The “startTime” and “duration” are displayed for each of the 16 images. Here are WebPagetest results for this test page being loaded in Chrome, IE10, and IE11. You can look at the screenshots to read the timing results. Note how “startTime” is approximately the same for all images. That’s because this is the time that the browser parsed the IMG tag and realized it needed to download the resource. But the “duration” values increase in steps of ~1 second for the images that occur later in the page. This is because they are blocked from downloading by the earlier images.
In Chrome, for example, the images are downloaded in three sets – because Chrome only downloads 6 resources at a time. The first six images have a “duration” of ~1.3 seconds (the 1 second backend delay plus some time for establishing the TCP connections and downloading the response body). The next six images have a “duration” of ~2.5 seconds. The last four images have a “duration” of ~3.7 seconds. The second set is blocked for ~1 second waiting for the first set to finish. The third set is blocked for ~2 seconds waiting for sets 1 & 2 to finish.
Even though the “duration” values increase from 1 to 2 to 3 seconds, the actual download time for all images is ~1 second as shown by the WebPagetest waterfall chart.

The results are similar for IE10 and IE11. IE10 starts with six parallel TCP connections but then ramps up to eight connections. IE11 also starts with six parallel TCP connections but then ramps up to twelve. Both IE10 and IE11 exhibit the same problem – even though the load time for every image is ~1 second, “duration” shows values ranging from 1-3 seconds.
proposal: “networkDuration”
Clearly, “duration” is not an accurate way to measure resource load times because it may include blocking time. (It also includes redirect time, but that occurs much less frequently.) Unfortunately, “duration” is the only metric available for cross-origin resources. Therefore, I’ve submitted a proposal to the W3C Web Performance mailing list to add “networkDuration” to Resource Timing. This would be available for both same-origin and cross-origin resources. (I’m flexible about the name; other candidates include “networkTime”, “loadTime”, etc.)
The calculation for “networkDuration” is as follows. (Assume “r” is a PerformanceResourceTiming object.)
dns = r.domainLookupEnd - r.domainLookupStart; tcp = r.connectEnd - r.connectStart; // includes ssl negotiation waiting = r.responseStart - r.requestStart; content = r.responseEnd - r.responseStart; networkDuration = dns + tcp + waiting + content;
Developers working with same-origin resources can do the same calculations as shown above to derive “networkDuration”. However, providing the result as a new attribute simplifies the process. It also avoids possible errors as it’s likely that companies and teams will compare these values, so it’s important to ensure an apples-to-apples comparison. But the primary need for “networkDuration” is for cross-origin resources. Right now, “duration” is the only metric available for cross-origin resources. I’ve found several teams that were tracking “duration” assuming it meant download time. They were surprised when I explained that it also including blocking time, and agreed it was not the metric they wanted; instead they wanted the equivalent of “networkDuration”.
I mentioned previously that the detailed time values (domainLookupStart, connectStart, etc.) are restricted to same-origin resources for privacy reasons. The proposal to add “networkDuration” is likely to raise privacy concerns; specifically that by removing blocking time, “networkDuration” would enable malicious third party JavaScript to determine whether a resource was read from cache. However, it’s possible to remove blocking time today using “duration” by loading a resource when there’s no blocking contention (e.g., after window.onload). Even when blocking time is removed, it’s ambiguous whether a resource was read from cache or loaded over the network. Even a cache read will have non-zero load times.
The problem that “networkDuration” solves is finding the load time for more typical resources that are loaded during page creation and might therefore incur blocking time.
Takeaway
It’s not possible today to use Resource Timing to measure load time for cross-origin resources. Companies that want to measure load time and blocking time can use “duration”, but all the companies I’ve spoken with want to measure the actual load time (without blocking time). To provide better performance metrics, I encourage the addition of “networkDuration” to the Resource Timing specification. If you agree, please voice your support in a reply to my “networkDuration” proposal on the W3C Web Performance mailing list.
do u webview?
A “webview” is a browser bundled inside of a mobile application producing what is called a hybrid app. Using a webview allows mobile apps to be built using Web technologies (HTML, JavaScript, CSS, etc.) but still package it as a native app and put it in the app store. In addition to allowing devs to work with familiar technologies, other advantages of building a hybrid app include greater code reuse across the app and the website, and easier support for multiple mobile platforms.
We all have webview traffic
Deciding whether to build a hybrid app versus a native app, or to have an app at all, is a lengthy debate and not the point of this post. Even if you don’t have a hybrid app, a significant amount of your mobile traffic comes from webviews. That’s because many sources of traffic are hybrid apps. Two examples on iOS are the Facebook app and Google Chrome. “Whoa, whoa, whoa” you say, Facebook’s retreat from its hybrid app is well known. That’s true. The Facebook timeline, for example, is no longer rendered using a webview:
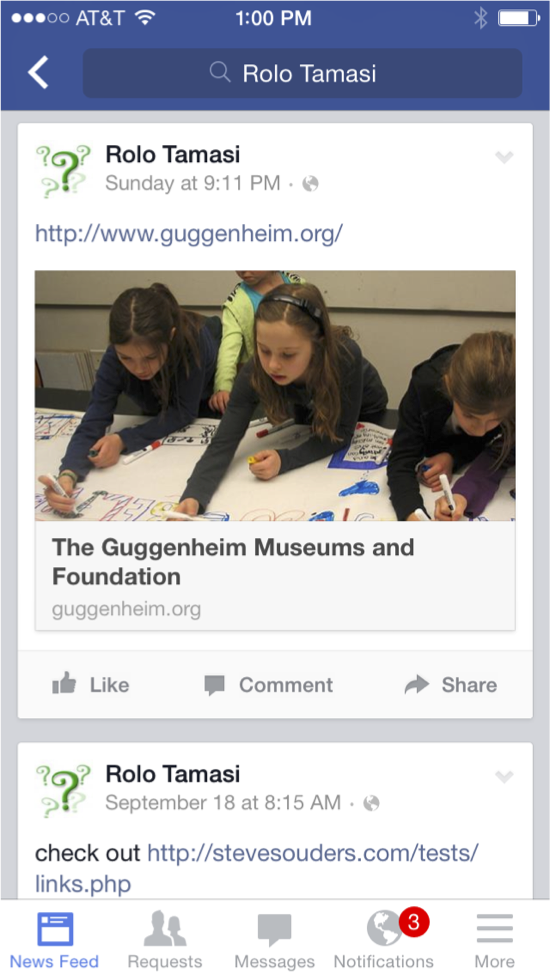
However, the Facebook timeline contains links, such as the link to http://www.guggenheim.org/ in the timeline above. When users click on links in the timeline, the Facebook app opens those in a webview:
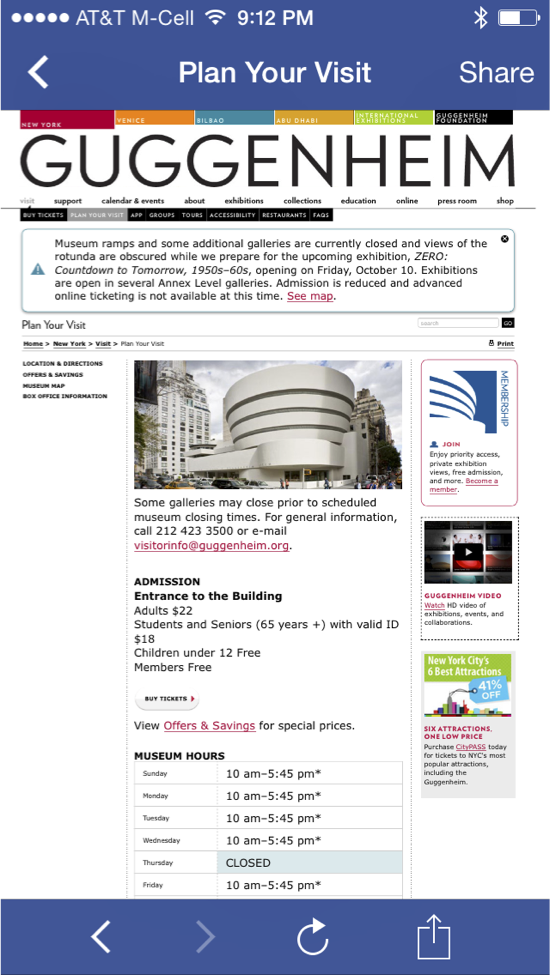
Similarly, Chrome for iOS is implemented using a webview. Across all iOS traffic, 6% comes from Facebook’s webview and 5% comes from Google Chrome according to ScientiaMobile. And there are other examples: Twitter’s iOS app uses a webview to render clicked links, etc.
I encourage you to scan your server logs to gauge how much of your mobile traffic comes from webviews. There’s not much documentation on webview User-Agent strings. For iOS, the User-Agent is typically a base string with information appended by the app. Here’s the User-Agent string for Facebook’s webview:
Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_1 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) Mobile/11D201 [FBAN/FBIOS;FBAV/12.1.0.24.20; FBBV/3214247; FBDV/iPhone6,1;FBMD/iPhone; FBSN/iPhone OS;FBSV/7.1.1; FBSS/2; FBCR/AT&T;FBID/phone;FBLC/en_US;FBOP/5]
Here’s the User-Agent string from Chrome for iOS:
Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) CriOS/37.0.2062.60 Mobile/11D257 Safari/9537.53
That’s a lot of detail. The bottom line is: we’re all getting more webview traffic than we expect. Therefore, it’s important that we understand how webviews perform and take that into consideration when building our mobile websites.
Webview performance
Since a webview is just a bundled browser, we might think that webviews and their mobile browser counterpart have similar performance profiles. It turns out that this is not the case. This was discovered as an unintentional side effect from the article iPhone vs. Android – 45,000 Tests Prove Who is Faster. This article from 2011, in the days of iOS 4.3, noted that the iPhone browser was 52% slower than Android’s. The results were so dramatic it triggered the following response from Apple:
[Blaze’s] testing is flawed. They didn’t actually test the Safari browser on the iPhone. Instead they only tested their own proprietary app, which uses an embedded Web viewer that doesn’t actually take advantage of Safari’s Web performance optimizations.
Apple’s response is accurate. The study conducted by Blaze (now part of Akamai) was conducted using a webview, so it was not a true comparison of the mobile browser from each platform. But the more important revelation is that webviews were hobbled resulting in worse performance than mobile Safari. Specifically, the webview on iOS 4.3 did not have Nitro’s JIT compiler for JavaScript, application cache, nor asynchronous script loading.
This means it’s not enough to track the performance of mobile browsers alone; we also need to track the performance of webviews. This is especially true in light of the fact that more than 10% of iOS traffic comes from webviews. Luckily, the state of webviews is better than it was in 2011. Even better, the most recent webviews have significantly more features when it comes to performance. The following table compares the most recent iOS and Android webviews along a set of important performance features.
| iOS 7 UIWebView |
iOS 8 WKWebView |
Android 4.3 Webkit Webview |
Android 4.4 Chromium Webview |
|
|---|---|---|---|---|
| Nitro/V8 | ✔ | ✔ | ||
| html5test.com | 410 | 440 | 278 | 434 |
| localStorage | ✔ | ✔ | ✔ | ✔ |
| app cache | ✔ | ✔ | ✔ | ✔ |
| indexedDB | ✔ | ✔ | ||
| SPDY | ✔ | ✔ | ||
| WebP | ✔ | |||
| srcset | ✔ | ? | ||
| WebGL | ✔ | ? | ||
| requestAnimation- Frame | ✔ | ✔ | ✔ | |
| Nav Timing | ✔ | ✔ | ✔ | |
| Resource Timing | ✔ |
As shown in this table, the newest webviews have dramatically better performance. The most important improvement is JIT compilation for JavaScript. While localStorage and app cache now have support across all webviews, the newer webviews add support for indexedDB. Support for SPDY in the newer webviews is important to help mitigate the impact of slow mobile networks. WebP, image srcset, and WebGL address the bloat of mobile images, but support for these features is mixed. (I wasn’t able to confirm the status of srcset and WebGL in Android 4.4’s webview. Please add comments and I’ll update the table.) The requestAnimationFrame API gives smoother animations. Finally, adoption of the Nav Timing and Resource Timing APIs gives website owners the ability to track performance for websites served inside webviews.
Not out of the woods yet
While the newest webviews have a better performance profile, we’re still on the hook for supporting older webviews. Hybrid apps will continue to use the older webviews until they’re rebuilt and updated. The Android webview is pinned at Chromium 30 and requires an OS upgrade to get feature updates. Similar to the issues with legacy browsers, traffic from legacy webviews will continue for at least a year. Given the significant amount of traffic from webviews and the dramatic differences in webview performance, it’s important that developers measure performance on old and new webviews, and apply mobile performance best practices to make their website as fast as possible even on old webviews.
(Many thanks to Maximiliano Firtman, Tim Kadlec, Brian LeRoux, and Guy Podjarny for providing information for this post.)
Prebrowsing
 A favorite character from the MASH TV series is Corporal Walter Eugene O’Reilly, fondly referred to as “Radar” for his knack of anticipating events before they happen. Radar was a rare example of efficiency because he was able to carry out Lt. Col. Blake’s wishes before Blake had even issued the orders.
A favorite character from the MASH TV series is Corporal Walter Eugene O’Reilly, fondly referred to as “Radar” for his knack of anticipating events before they happen. Radar was a rare example of efficiency because he was able to carry out Lt. Col. Blake’s wishes before Blake had even issued the orders.
What if the browser could do the same thing? What if it anticipated the requests the user was going to need, and could complete those requests ahead of time? If this was possible, the performance impact would be significant. Even if just the few critical resources needed were already downloaded, pages would render much faster.
Browser cache isn’t enough
You might ask, “isn’t this what the cache is for?” Yes! In many cases when you visit a website the browser avoids making costly HTTP requests and just reads the necessary resources from disk cache. But there are many situations when the cache offers no help:
- first visit – The cache only comes into play on subsequent visits to a site. The first time you visit a site it hasn’t had time to cache any resources.
- cleared – The cache gets cleared more than you think. In addition to occasional clearing by the user, the cache can also be cleared by anti-virus software and browser bugs. (19% of Chrome users have their cache cleared at least once a week due to a bug.)
- purged – Since the cache is shared by every website the user visits, it’s possible for one website’s resources to get purged from the cache to make room for another’s.
- expired – 69% of resources don’t have any caching headers or are cacheable for less than one day. If the user revisits these pages and the browser determines the resource is expired, an HTTP request is needed to check for updates. Even if the response indicates the cached resource is still valid, these network delays still make pages load more slowly, especially on mobile.
- revved – Even if the website’s resources are in the cache from a previous visit, the website might have changed and uses different resources.
Something more is needed.
Prebrowsing techniques
In their quest to make websites faster, today’s browsers offer a number of features for doing work ahead of time. These “prebrowsing” (short for “predictive browsing” – a word I made up and a domain I own) techniques include:
<link rel="dns-prefetch" ...><link rel="prefetch" ...><link rel="prerender" ...>- DNS pre-resolution
- TCP pre-connect
- prefreshing
- the preloader
These features come into play at different times while navigating web pages. I break them into these three phases:
- previous page – If a web developer has high confidence about which page you’ll go to next, they can use LINK REL dns-prefetch, prefetch or prerender on the previous page to finish some work needed for the next page.
- transition – Once you navigate away from the previous page there’s a transition period after the previous page is unloaded but before the first byte of the next page arrives. During this time the web developer doesn’t have any control, but the browser can work in anticipation of the next page by doing DNS pre-resolution and TCP pre-connects, and perhaps even prefreshing resources.
- current page – As the current page is loading, browsers have a preloader that scans the HTML for downloads that can be started before they’re needed.
Let’s look at each of the prebrowsing techniques in the context of each phase.
Phase 1 – Previous page
As with any of this anticipatory work, there’s a risk that the prediction is wrong. If the anticipatory work is expensive (e.g., steals CPU from other processes, consumes battery, or wastes bandwidth) then caution is warranted. It would seem difficult to anticipate which page users will go to next, but high confidence scenarios do exist:
- If the user has done a search with an obvious result, that result page is likely to be loaded next.
- If the user navigated to a login page, the logged-in page is probably coming next.
- If the user is reading a multi-page article or paginated set of results, the page after the current page is likely to be next.
Let’s take the example of searching for Adventure Time to illustrate how different prebrowsing techniques can be used.
DNS-PREFETCH
If the user searched for Adventure Time then it’s likely the user will click on the result for Cartoon Network, in which case we can prefetch the DNS like this:
<link rel="dns-prefetch" href="//cartoonnetwork.com">
DNS lookups are very low cost – they only send a few hundred bytes over the network – so there’s not a lot of risk. But the upside can be significant. This study from 2008 showed a median DNS lookup time of ~87 ms and a 90th percentile of ~539 ms. DNS resolutions might be faster now. You can see your own DNS lookup times by going to chrome://histograms/DNS (in Chrome) and searching for the DNS.PrefetchResolution histogram. Across 1325 samples my median is 50 ms with an average of 236 ms – ouch!
In addition to resolving the DNS lookup, some browsers may go one step further and establish a TCP connection. In summary, using dns-prefetch can save a lot of time, especially for redirects and on mobile.
PREFETCH
If we’re more confident that the user will navigate to the Adventure Time page and we know some of its critical resources, we can download those resources early using prefetch:
<link rel="prefetch" href="http://cartoonnetwork.com/utils.js">
This is great, but the spec is vague, so it’s not surprising that browser implementations behave differently. For example,
- Firefox downloads just one prefetch item at a time, while Chrome prefetches up to ten resources in parallel.
- Android browser, Firefox, and Firefox mobile start prefetch requests after window.onload, but Chrome and Opera start them immediately possibly stealing TCP connections from more important resources needed for the current page.
- An unexpected behavior is that all the browsers that support prefetch cancel the request when the user transitions to the next page. This is strange because the purpose of prefetch is to get resources for the next page, but there might often not be enough time to download the entire response. Canceling the request means the browser has to start over when the user navigates to the expected page. A possible workaround is to add the “Accept-Ranges: bytes” header so that browsers can resume the request from where it left off.
It’s best to prefetch the most important resources in the page: scripts, stylesheets, and fonts. Only prefetch resources that are cacheable – which means that you probably should avoid prefetching HTML responses.
PRERENDER
If we’re really confident the user is going to the Adventure Time page next, we can prerender the page like this:
<link rel="prerender" href="http://cartoonnetwork.com/">
This is like opening the URL in a hidden tab – all the resources are downloaded, the DOM is created, the page is laid out, the CSS is applied, the JavaScript is executed, etc. If the user navigates to the specified href, then the hidden page is swapped into view making it appear to load instantly. Google Search has had this feature for years under the name Instant Pages. Microsoft recently announced they’re going to similarly use prerender in Bing on IE11.
Many pages use JavaScript for ads, analytics, and DHTML behavior (start a slideshow, play a video) that don’t make sense when the page is hidden. Website owners can workaround this issue by using the page visibility API to only execute that JavaScript once the page is visible.
Support for dns-prefetch, prefetch, and prerender is currently pretty spotty. The following table shows the results crowdsourced from my prebrowsing tests. You can see the full results here. Just as the IE team announced upcoming support for prerender, I hope other browsers will see the value of these features and add support as well.
| dns-prefetch | prefetch | prerender | |
|---|---|---|---|
| Android 4 | 4 | ||
| Chrome | 22+ | 31+1 | 22+ |
| Chrome Mobile | 29+ | ||
| Firefox | 22+2 | 23+2 | |
| Firefox Mobile | 24+ | 24+ | |
| IE | 113 | 113 | 113 |
| Opera | 15+ |
- 1 Need to use the
--prerender=enabledcommandline option. - 2 My friend at Mozilla said these features have been present since version 12.
- 3 This is based on a Bing blog post. It has not been tested.
Ilya Grigorik‘s High Performance Networking in Google Chrome is a fantastic source of information on these techniques, including many examples of how to see them in action in Chrome.
Phase 2 – Transition
When the user clicks a link the browser requests the next page’s HTML document. At this point the browser has to wait for the first byte to arrive before it can start processing the next page. The time-to-first-byte (TTFB) is fairly long – data from the HTTP Archive in BigQuery indicate a median TTFB of 561 ms and a 90th percentile of 1615 ms.
During this “transition” phase the browser is presumably idle – twiddling its thumbs waiting for the first byte of the next page. But that’s not so! Browser developers realized that this transition time is a HUGE window of opportunity for performance prebrowsing optimizations. Once the browser starts requesting a page, it doesn’t have to wait for that page to arrive to start working. Just like Radar, the browser can anticipate what will need to be done next and can start that work ahead of time.
DNS pre-resolution & TCP pre-connect
The browser doesn’t have a lot of context to go on – all it knows is the URL being requested, but that’s enough to do DNS pre-resolution and TCP pre-connect. Browsers can reference prior browsing history to find clues about the DNS and TCP work that’ll likely be needed. For example, suppose the user is navigating to http://cartoonnetwork.com/. From previous history the browser can remember what other domains were used by resources in that page. You can see this information in Chrome at chrome://dns. My history shows the following domains were seen previously:
- ads.cartoonnetwork.com
- gdyn.cartoonnetwork.com
- i.cdn.turner.com
During this transition (while it’s waiting for the first byte of Cartoon Network’s HTML document to arrive) the browser can resolve these DNS lookups. This is a low cost exercise that has significant payoffs as we saw in the earlier dns-prefetch discussion.
If the confidence is high enough, the browser can go a step further and establish a TCP connection (or two) for each domain. This will save time when the HTML document finally arrives and requires page resources. The Subresource PreConnects column in chrome://dns indicates when this occurs. For more information about dns-presolution and tcp-preconnect see DNS Prefetching.
Prefresh
Similar to the progression from LINK REL dns-prefetch to prefetch, the browser can progress from DNS lookups to actual fetching of resources that are likely to be needed by the page. The determination of which resources to fetch is based on prior browsing history, similar to what is done in DNS pre-resolution. This is implemented as an experimental feature in Chrome called “prefresh” that can be turned on using the --speculative-resource-prefetching="enabled" flag. You can see the resources that are predicted to be needed for a given URL by going to chrome://predictors and clicking on the Resource Prefetch Predictor tab.
The resource history records which resources were downloaded in previous visits to the same URL, how often the resource was hit as well as missed, and a score for the likelihood that the resource will be needed again. Based on these scores the browser can start downloading critical resources while it’s waiting for the first byte of the HTML document to arrive. Prefreshed resources are thus immediately available when the HTML needs them without the delays to fetch, read, and preprocess them. The implementation of prefresh is still evolving and being tested, but it holds potential to be another prebrowsing timesaver that can be utilized during the transition phase.
Phase 3 – Current Page
Once the current page starts loading there’s not much opportunity to do prebrowsing – the user has already arrived at their destination. However, given that the average page takes 6+ seconds to load, there is a benefit in finding all the necessary resources as early as possible and downloading them in a prioritized order. This is the role of the preloader.
Most of today’s browsers utilize a preloader – also called a lookahead parser or speculative parser. The preloader is, in my opinion, the most important browser performance optimization ever made. One study found that the preloader alone improved page load times by ~20%. The invention of preloaders was in response to the old browser behavior where scripts were downloaded one-at-a-time in daisy chain fashion.
Starting with IE 8, parsing the HTML document was modified such that it forked when an external SCRIPT SRC tag was hit: the main parser is blocked waiting for the script to download and execute, but the lookahead parser continues parsing the HTML only looking for tags that might generate HTTP requests (IMG, SCRIPT, LINK, IFRAME, etc.). The lookahead parser queues these requests resulting in a high degree of parallelized downloads. Given that the average web page today has 17 external scripts, you can imagine what page load times would be like if they were downloaded sequentially. Being able to download scripts and other requests in parallel results in much faster pages.
The preloader has changed the logic of how and when resources are requested. These changes can be summarized by the goal of loading critical resources (scripts and stylesheets) early while loading less critical resources (images) later. This simple goal can produce some surprising results that web developers should keep in mind. For example:
- JS responsive images get queued last – I’ve seen pages that had critical (bigger) images that were loaded using a JavaScript responsive images technique, while less critical (smaller) images were loaded using a normal IMG tag. Most of the time I see these images being downloaded from the same domain. The preloader looks ahead for IMG tags, sees all the less critical images, and adds those to the download queue for that domain. Later (after DOMContentLoaded) the JavaScript responsive images technique kicks in and adds the more critical images to the download queue – behind the less critical images! This is often not the expected nor desired behavior.
- scripts “at the bottom” get loaded “at the top” – A rule I promoted starting in 2007 is to move scripts to the bottom of the page. In the days before preloaders this would ensure that all the requests higher in the page, including images, got downloaded first – a good thing when the scripts weren’t needed to render the page. But most preloaders give scripts a higher priority than images. This can result in a script at the bottom stealing a TCP connection from an image higher in the page causing above-the-fold rendering to take longer.
When it comes to the preloader the bottomline is that the preloader is a fantastic performance optimization for browsers, but the logic is new and still evolving so web developers should be aware of how the preloader works and watch their pages for any unexpected download behavior.
As the low hanging fruit of web performance optimization is harvested, we have to look harder to find the next big wins. Prebrowsing is an area that holds a lot of potential to deliver pages instantly. Web developers and browser developers have the tools at their disposal and some are taking advantage of them to create these instant experiences. I hope we’ll see even wider browser support for these prebrowsing features, as well as wider adoption by web developers.
[Here are the slides and video of my Prebrowsing talk from Velocity New York 2013.]
ActiveTable bookmarklet
I write a lot of code that generates HTML tables. If the code gets a lot of use, I’ll go back later and integrate my default JavaScript library to do table sorting. (My code is based on Standardista Table Sorting by Neil Crosby.) In addition to sorting, sometimes it’s nice to be able to hide superfluous columns. For example, the HTTP Archive page for viewing a single website’s results (e.g., WholeFoods) has a table with 39 columns! I wrote some custom JavaScript to allow customizing which columns were displayed. But generally, I generate tables that aren’t sortable and have fixed columns.
It turns out, this is true for many websites. Each day I visit a few pages with a table that I wish was sortable. Sometimes there are so many columns I wish I could hide the less important ones. This is especially true if my 13″ screen is the only monitor available.
This problem finally became big enough that I wrote a bookmarklet to solve the problem: activetable.js
Here’s how to use it:
1. Add this ActiveTable bookmarklet link to your bookmarks. (Drag it to your Bookmarks toolbar, or right-click and add the link to your bookmarks.)
2. Go to a page with a big table. For example, Show Slow. Once that page is loaded, click on the ActiveTable bookmark. This loads activetable.js which makes the table sortable and customizable. The table’s header row is briefly highlighted in blue to indicate it’s active.
3. Hover over a column you want to sort or remove. The ActiveTable widget is displayed:

4. Click on the sort icon to toggle between ascending and descending. Click on the red “X” to hide the column. To UNhide all columns just alt+click on any TH element.
Another nice feature of ActiveTable is the columns you choose to hide are stored in localStorage. The next time you come to the same page and launch ActiveTable, you’re asked if you want to hide the same columns again.
CAVEATS: I’ve only tested the code on Chrome and Firefox. Tables with TD cells that span multiple rows or columns may not work as expected.
You can test it out on these real world pages:
- Voting Record For Feinstein – This table is 20 pages long and doesn’t have any way to sort.Â
- World University Rankings – This table is already sortable, but sorting the table causes the entire page to reload. ActiveTable does sorting in place, without a reload.
- Imdb All-Time USA Box office – Even though this table has 557 rows, it’s not sortable. ActiveTable allows sorting, but sorts the dollar values alphabetically.
I love having my Web my way. ActiveTable makes it more enjoyable for me to wade through the massive tables I encounter every day.
Twitter widget update
A few weeks ago I had Chrome Dev Tools open while loading my personal website and noticed the following console messages:

I have a Twitter widget in my web page. I think this notice of deprecation is interesting. I use several 3rd party widgets and have never noticed a developer-targeted warning like this. Perhaps it’s done frequently, but this was the first time I saw anything like this.
I really appreciated the heads up. The previous Twitter widget loaded a script synchronously causing bad performance. I had “asyncified” the snippet by reverse engineering the code. (See slides 11-18 from my Fluent High Performance Snippets presentation.) This was about an hour of work and resulted in ~40 lines of additional JavaScript in my page.
The new Twitter snippet is asynchronous – yay! I’m able to replace my hack with one line of markup and one line of JavaScript. All the options I want (size, color, etc.) are available. I just did the update today and am looking forward to seeing if it reduces my onload metrics.
Getting consumers to update old snippet code is a challenge for snippet owners. This is why so many sites use bootstrap scripts. The downside is bootstrap scripts typically result in two script downloads resulting in a slower snippet rendering time.
An interesting study that could be done with data from the HTTP Archive would be to analyze the adoption of new snippets. For example, tracking the migration from urchin.js to ga.js, or widgets.twimg.com/.../widget.js to platform.twitter.com/widgets.js. This would require a way to identify the before and after script. Correlating this with the techniques used to motivate website owners to change their code could help identify some best practices.
Twitter’s technique of logging warnings to console worked for me, but I don’t know how long ago they offered the async snippet version. Perhaps I’ve been lagging for months. I bet we could identify other good (and bad) techniques for evangelizing a massive code upgrade for third party widgets. That would be a good thing.
Browser Busy Indicators
I’m doing research on the perception of speed for my Ignite Velocity talk. The perception of website speed is obviously fueled by what the user sees in the browser. While the content of a website is controlled by the website owner, the browser also provides feedback to the user. This browser feedback affects user perception of website speed. Good developers need to understand how their code affects what users see, including the browser feedback that’s triggered (or not triggered).
Busy Indicators
Let’s start by enumerating the browser’s feedback mechanisms. I’ve identified six ways that browsers give feedback when they’re busy doing some action:

- tab icon – This is typically the site’s favicon. It turns to a spinner when that tab is busy.
- status bar – Some browsers display a message about outstanding requests in the status bar.
- reload icon – The reload icon (typically a circular arrow) changes to an “X” during downloads.
- progress bar – Some browsers have a progress bar. Opera shows the fraction of completed downloads:

- network busy – iOS shows a busy indicator whenever there’s network traffic. (Technically this is outside the browser but I included it since it’s a strong visual cue at the top of the screen.)
- cursor – In some situations the cursor changes to a “progress cursor”.
Test Scenarios
The browser busy indicators are triggered during normal web surfing such as clicking links. They’re also triggered by some of the dynamic behaviors popular in today’s web pages. I came up with this list of scenarios under which to measure browser busy indicators:
- click link – Click a link to another web page.
- async script – The HTML document contains
<SCRIPT ASYNC SRC="...">. - dynamic script before onload – The HTML document loads a script usingÂ
document.createElement('script') andappendChild(). - dynamic iframe – Clicking a button initiates the loading of an iframe usingÂ
document.createElement('iframe')Â andÂappendChild(). - dynamic script – Same as dynamic iframe but with a script.
- dynamic stylesheet – Same as dynamic iframe but with a stylesheet.
- dynamic image – Same as dynamic iframe but with an image.
- dynamic background image – Same as dynamic iframe but with a CSS background image.
- XHR – Clicking a button initiates an XMLHttpRequest.
- long JS loop – Clicking a button initiates some JavaScript that loops for a few seconds.
I chose these scenarios to mimic real world situations. For example, many single page web apps use XHR – do those trigger any browser busy indicators? Photo carousels often fetch images dynamically – does the user get any feedback from the browser when that happens?
You can see the specific code for each scenario on this test page. I ran each scenario across the major browsers and recorded the results in a Browserscope user test.
Results
Many of the test cases didn’t trigger any of the browser busy indicators: dynamic script, dynamic stylesheet, dynamic image, dynamic background image, XHR, and long JS loop. (Except on iOS the network spinner was triggered for every test that involved an HTTP request.) I didn’t include these tests in the results table. The results for click link, async script, dynamic script before onload, and dynamic iframe are shown in the following table.
| browser | click link | async script | dynamic script before onload |
dynamic iframe |
|---|---|---|---|---|
| Chrome 27 (Mac OS) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Chrome 27 (Windows) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Firefox 21 (Mac OS) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Firefox 21 (Windows) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| IE 9 (Windows) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Opera 12 (Mac OS) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Opera 12 (Windows) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Safari 6 (Mac OS) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Safari 5 (Windows) | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Mobile: | ||||
| Android 4 | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Chrome Mobile 26 | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
| Mobile Safari 6 | TSCPRN | TSCPRN | TSCPRN | TSCPRN |
Each result is essentially a bitmask indicating whether the busy indicator was triggered. For example, the first result for “Chrome 27 (Mac OS)” and the “click link” test is TSCPRN. This means the Tab icon, Status bar, and Reload icon indicators were triggered; but the Cursor, Progress bar, and Network indicators were not triggered. A few notes about the indicators:
- The network indicator is only applicable for Mobile Safari.
- The progress bar indicator is only applicable for Opera, Safari, Android, Chrome Mobile, and Mobile Safari.
- Mobile browsers don’t have tabs, status bars, nor cursors (currently) so those indicators aren’t applicable.
Takeaways
The purpose of these tests is to see how the browser busy indicators might affect the user’s perception of speed under different scenarios. The tests themselves are contrived, but it’s easy (and necessary) to put them in the context of a web page.
For example, if a feature involves a JSON request, which technique should be used? These browser busy indicators provide some guidance. If the JSON data is asynchronous to the user experience, such as updating stock quotes or friends’ online status, then it would be better to not trigger the browser busy indicators. Doing so would make the user pause their current actions and wonder what the web page was doing. Conversely, if the feature was synchronous to the user experience, such as opening a mail folder, then it would be better to give the user feedback that the action was being performed.
In this context we note that the dynamic iframe technique triggers busy indicators in some browsers. Therefore, this would be a bad choice for background tasks. And if it was chosen for a synchronous action it should be augmented to provide feedback across all browsers (such as a progress icon or busy spinner).
One of the biggest takeaways for me was that the progress cursor is only triggered on Windows. I find this to be a primary feedback mechanism when using the mouse – especially when clicking a link. These Mozilla bug comments seem to point to this being a Mac OS design guideline. I find it distracting on Mac OS to have to move my eye away from where I’m focusing in order to get feedback that my click was “heard”.
On the note of techniques that do not trigger busy indicators, almost all of the dynamic loading techniques fall into this category, the exception being dynamic iframe. (By “dynamic loading” I mean using JavaScript to initiate the HTTP request.)Â This is good and bad. Often dynamic images are used to beacon back metrics and logging information. It’s good to know these beacons aren’t interfering with the user experience. On the other hand, if a synchronous feature loads scripts dynamically, it might be necessary to provide other feedback to the user that the action is being carried out.
These busy indicators have an impact on the user’s perception of website speed. Triggering busy indicators for actions that are supposed to be in the background brings them to the user’s attention making the experience feel slower. If a user’s action is synchronous but there’s no feedback, that’s frustrating and makes the experience seem longer than it actually is. We can produce better user experiences by taking these tradeoffs into consideration and avoiding them or augmenting them depending on the situation.
How fast are we going now?
[This blog post is based on my keynote at the HTML5 Developer Conference. The slides are available on SlideShare and as PPTX.]
I enjoy evangelizing web performance because I enjoy things that are fast (and efficient). Apparently, I’m not the only one. Recent ad campaigns, especially for mobile, tout the virtues of being fast. Comcast uses the words “speed”, “fastest”, “high-speed”, and “lightning-fast” in the Xfinity ads. AT&T’s humorous set of commercials talks about how “faster is better“. iPhone’s new A6 chip is touted as “twice as fast“.
Consumers, as a result of these campaigns selling speed, have higher expectations for the performance of websites they visit. Multiple case studies support the conclusion that a faster website is better received by users and has a positive impact on the business’s bottom line:
- Bing found that searches that were 2 seconds slower resulted in a 4.3% drop in revenue per user.
- When Mozilla shaved 2.2 seconds off their landing page, Firefox downloads increased 15.4%.
- Shopzilla saw conversion rates increase 7-12% as a result of their web performance optimization efforts.
- Making Barack Obama’s website 60% faster increased donation conversions 14%.
Vendors are pitching a faster web. Consumers are expecting a faster web. Businesses succeed with a faster web. But is the Web getting faster? Let’s take a look.
Connection Speed
A key to a faster web experience is a faster Internet connection, but this aspect of web performance often feels like a black box. Users and developers are at the mercy of the ISPs and carrier networks. Luckily, data from Akamai’s State of the Internet shows that connection speeds are increasing.
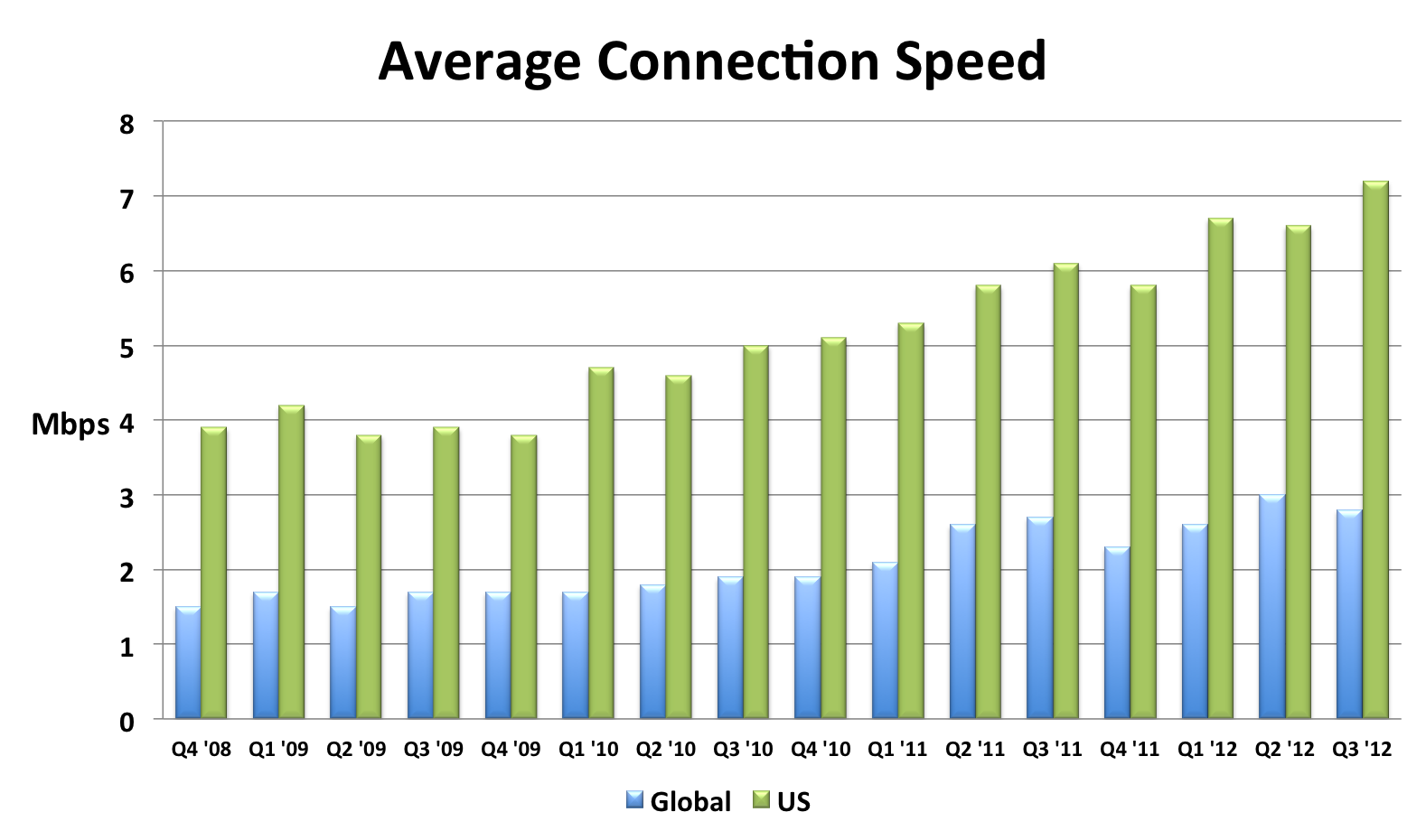
I compiled this chart by extracting the relevant data from each quarterly report. The chart shows that global connection speeds increased 4% and US connection speeds increased 18% over the most recent year that data exists (Q3 2011 to Q3 2012). I also created an Average Mobile Connection Speed chart which tracks three mobile carrier networks. Akamai masks the carrier network name but over the last year the connection speed of these mobile networks increased 30%, 68%, and 131%.
{kind=link}
Browsers
Speed is a major feature for browsers. This focus has resulted in many performance improvements over the last few years. In my opinion browser improvements are the biggest contributor to a faster web. I’ll sidestep the contentious debate about which browser is fastest, and instead point out that, regardless of which one you choose, browsers are getting faster with each release.
The following chart shows page load times for major browsers as measured from real users. This report from Gomez is a bit dated (August 2011), but it’s the only real user data I’ve seen broken out by browser. Notice the trends for new releases – page load times improve 15-30%.

The other major benchmark for browsers is JavaScript performance. Below are charts from ZDNet’s browser benchmark report. Except for a regression in Firefox 18, all the trends are showing that browsers get faster with each release.


Page Weight
Web developers don’t have much control over connection speeds and browser optimizations, but they can control the size of their pages. Unfortunately, page weight continues to increase. The data below is from the HTTP Archive for the world’s top 1000 URLs. It shows that transfer size (number of bytes sent over the wire) increased 231K (28%) from March 2012 to March 2013. The biggest absolute increase was in images – growing 114K (23%). The biggest surprise, for me, was the growth in video by 62K (67%). This increase comes from two main factors: more sites are including video and the size of videos are increasing. Video performance is an area that we need to focus on going forward.
| Table 1. Transfer Size Year over Year | |||
| Mar 2012 | Mar 2013 | Δ | |
|---|---|---|---|
| total | 822 K | 1053 K | 231 K (28%) |
| images | 486 K | 600 K | 114 K (23%) |
| JS | 163 K | 188 K | 25 K (15%) |
| video | 92 K | 154 K | 62 K (67%) |
| HTML | 35 K | 42 K | 7 K (20%) |
| CSS | 30 K | 36 K | 6 K (20%) |
| font | 8 K | 18 K | 10 K (125%) |
| other | 8 K | 15 K | 7 K (88%) |
Quality of Craft
There are several “performance quality” metrics tracked in the HTTP Archive. Like page weight, these metrics are something that web developers have more control over. Unfortunately, these metrics were generally flat or trending down for the world’s top 1000 URLs. These metrics are hard to digest in bulk because sometimes higher is better, and other times it’s worse. There’s more detail below but the punchline is 5 of the 7 metrics got worse, and the other two were nearly flat.
| Table 2. Quality of Craft Metrics Year over Year | ||
| Mar 2012 | Mar 2013 | |
|---|---|---|
| PageSpeed Score | 82 | 84 |
| DOM Elements | 1215 | 1330 |
| # of Domains | 15 | 19 |
| Max Reqs on 1 Domain | 40 | 41 |
| Cacheable Resources | 62% | 60% |
| Compressed Responses | 76% | 77% |
| Pages w/ Redirects | 67% | 71% |
Here’s a description of each of these metrics and how they impact web performance.
- PageSpeed Score – PageSpeed is a performance “lint” analysis tool that generates a score from 0 to 100, where 100 is good. YSlow is a similar tool. Year over year the PageSpeed Score increased from 82 to 84, a (small) 2% improvement.
- DOM Elements – The number of DOM elements affects the complexity of a page and has a high correlation to page load times. The number of DOM elements increased from 1215 to 1330, meaning pages are getting more complex.
- # of Domains – The average number of domains per page increased from 15 to 19. More domains means there are more DNS lookups, which slows down the page. This is likely due to the increase in 3rd party content across the Web.
- Max Reqs on 1 Domain – The average top 1000 web page today has 100 requests spread across 19 domains. That averages out to ~5 requests per domain. But the distribution of requests across domains isn’t that even. The HTTP Archive counts how many requests are made for each domain, and then records the domain that has the maximum number of requests – that’s the “Max Reqs on 1 Domain” stat. This increased from 40 to 41. This is a bad trend for performance because most browsers only issue 6 requests in parallel, so it takes seven “rounds” to get through 41 requests. These sites would be better off adopting domain sharding.
- Cacheable Resources – Pages are faster if resources are read from cache, but that requires website owners to set the appropriate caching headers. This stat measures the percentage of requests that had a cache lifetime greater than zero. Unfortunately, the percentage of cacheable resources dropped from 62% to 60%.
- Compressed Responses – The transfer size of text responses (HTML, scripts, stylesheets, etc.) can be reduced ~70% by compressing them. It doesn’t make sense to compress binary data such as images and video. This stat shows the percentage of requests that should be compressed that actually were compressed. The number increased but just slightly from 76% to 77%.
- Pages with Redirects – Redirects slow down pages because an extra roundtrip has to be made to fetch the final response. The percentage of pages with at least one redirect increased from 67% to 71%.
These drops in performance quality metrics is especially depressing to me since evangelizing performance best practices is a large part of my work. It’s especially bad since this only looks at the top 1000 sites which typically have more resources to focus on performance.
User Experience
The ultimate goal isn’t to improve these metrics – it’s to improve the user experience. Unfortunately, we don’t have a way to measure that directly. The metric that’s used as a proxy for the user’s perception of website speed is “page load time” – the time from when the user initiates the request for the page to the time that window.onload fires. Many people, including myself, have pointed out that window.onload is becoming less representative of a web page’s perceived speed, but for now it’s the best we have.
Perhaps the largest repository of page load time data is in Google Analytics. In April 2013 the Google Analytics team published their second report on the speed of the web where they compare aggregate page load times to a year ago. The median page load time on desktops got ~3.5% faster, and on mobile was ~18%Â ~30% faster.

Scorecard
Web pages have gotten bigger. The adoption of performance best practices has been flat or trending down. Connection speeds and browsers have gotten faster. Overall, web pages are faster now than they were a year ago. I think browser vendors deserve most of the credit for this speed improvement. Going forward, web developers will continue to be pushed to add more content, especially 3rd party content, to their sites. Doing this in a way that follows performance best practices will help to make the Web even faster for next year.